Data Structure
1 树
1.1 一些定义
- 满二叉树:全满.
- 完全二叉树:只有最后一层不全满,但是是从左到右填满的.
1.2 一些性质
1.2.1 完全二叉树
一个位置为=i=的节点,其左孩子为=2i=,父节点为⌊i/2⌋
1.3 二叉查找树
对于树中每一个节点,其左子树中所有关键字值小于该节点关键字值,右子树中所有关键字值大于之。
1.3.1 删除操作
- 若要删除的节点是一片树叶,直接删。
- 若该节点有一个子节点,用该子节点代替它。
- 若有两个子节点,使用其右子树中最小的数据代替该节点,再将那个最小的数据的节点(此时是空的)删除(它没有左子树)。
如果删除的次数不多,通常使用=惰性删除=:当一个元素被删除时,它仍留在树中,只是做了删除的标记.
1.4 AVL树
带有平衡条件的二叉查找树.
设计要点:
- 平衡条件容易保持
- 必须保证树的深度是=O(logN)=
常用的定义:每个节点的左子树和右子树的高度最多差1的二叉查找树.下图中左边是,右边不是.

插入节点时,树的平衡容易被破坏,要通过旋转操作修复.
插入有四种情况:
- 左左: 节点插入成左子树的左子树.
- 右右
- 左右: 节点插入成左子树的右子树
- 右左
1,2等价,3,4等价.
1,2需要进行=单旋转=.3,4需要进行=双旋转=
1.4.1 单旋转
下图中X比Z深2,需要修复.
- 把=k1=拎起来
- =Y=挂到=k2=的左子树上
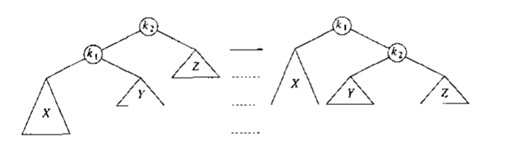
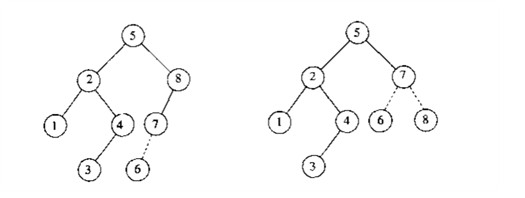
下面是一个实际的例子
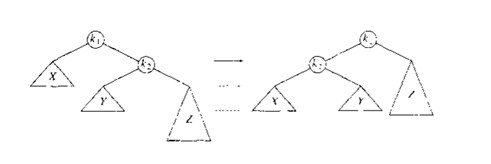
1.4.2 双旋转
k2那个分支太深了,单旋转解决不了.双旋转修复法:
- 把=k2=拎起来
B,=C=分别放到左右子树上.
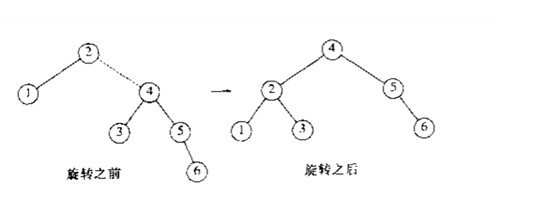
下面是实际的例子.
2 堆
堆又叫=优先队列=.
堆有至少如下操作:
- Insert
- DeleteMin
一般的实现都使用=二叉堆=,经常把之简称=堆=.
堆是一个=完全二叉树=.
堆序性:堆中每一个节点都小于或等于其后裔.最小元在根上.
2.1 Insert
上滤:
- 在该=完全二叉树=的下一个空闲位置建立一个空穴.
- 如果=X=可以放入其中而不破坏=堆序性=,结束
- 否则,将该空穴的父节点放过来,再尝试将=X=放入.
- 循环.
2.2 DeleteMin
下滤:
- 将根删除
- 将最后一个数据视为
X,需要将它移动到一个正确的位置.
所以步骤为:
- 删根
- 将
X放入空穴,如果不破坏堆序性,结束 - 否则,将空穴的子节点中最小的一个移入空穴,尝试将=X=放入新空穴
- 循环
3 排序
3.1 插入排序
在第 P 趟,将位置 P 上的元素向左移动到它在前 P+1 个元素的正确位置上.
3.2 希尔排序
又叫 缩小增量排序
使用一个 增量序列: h1,h2,...,hk

上图中,使用的增量序列是 1,3,5.
每一行是一次排序.
第一行中,对 1,6,11, 2,7,12, 3,8,13 等分别排序.
第二行中,对 1,4,7,10, 2,5,8,11 等单独排序.
最坏复杂度: \(O(N^2)\).但是好的增量序列往往比堆排序还快.
3.3 堆排序
建立N个元素的二叉堆,花费 \(O(N)\) 时间.
然后执行N次 DeleteMin 操作输出结果,每次 O(N).
总时间复杂度: \(O(NlogN)\)
3.3.1 额外阅读
DeleteMin 输出结果时,要使用另一个数组.可以避免的.方法是将出来的放到最后新空出来的空穴中.
这样就会最终得到一个递减的序列.
为了得到递增的序列,可以使用=max堆=,即根是最大的.
3.4 归并排序
基本操作是合并两个已经排序的表.
void MSort(ElementType A[], ElementType TmpArray[], int Left, int Right) { int Center; if (Left<Right) { Center = (Left+Right)/2; MSort(A, TmpArray, Left, Center); MSort(A, TmpArray, Center+1, Right); Merge(A, TmpArrray, Center+1, Right); } }
Merge函数用来连接两个已经排序的表.
最小的已排序的表是只包含一个元素的表.
最坏情形的时间复杂度 \(O(NlogN)\)
3.5 快速排序
快速排序是在实践中最快的已知排序算法.
平均运行时间 \(O(NlogN)\), 最坏性能 \(O(N^2)\),但稍加努力就可以避免这种情况.
步骤:
- 在s中取任意一个元素
v,称为枢纽元 - 把s中比
v小的放左边,比v大的放右边. - 对两边各进行快速排序
3.5.1 选取枢纽元
3.5.1.1 错误的方法
使用第一个元素
3.5.1.2 安全的做法
随机选取.但是不好,随机数生成一般是昂贵的.
3.5.1.3 三数中值分割法
最好的方法是使用数组的中值,但是计算昂贵.
一般选取左端,右端,中心位置这三个元素作为枢纽元.
3.5.2 分割策略
已知枢纽元,如何将小的放前面,大的放后面?
- 将枢纽元与最后的元素交换
i指向第一个元素,j指向倒数第二个元素- 将
i右移,移过比枢纽元小的元素.将j左移,移过比枢纽元大的元素 - 当
i和j都停止时,交换i和j的数据,并重复步骤3 - 当
i和j交错了,即i跑到j的右侧了,将i的值和枢纽元交换
4 图
4.1 一些定义
无向图是连通的: 一个无向图,每一个顶点到其他顶点都存在一条路径有向图是强连通的: 具有如上性质的有向图.
4.2 拓扑排序
拓扑排序是对有向无圈图的顶点的一种排序,使得如果存在vi到vj的路径,那么在排序中vi在vj前面.
也就是要满足课程先修得条件.
4.2.1 一个简单的算法
- 在图中找到一个入度为0的点
- 将它的邻接点得入度–
- 将它放入拓扑序列中
for(all vertex) {
v = findVertexOfIndegreeZero();
for each w adjacent to v {
Indegree[w]--;
}
}
使用队列的算法
q = createQueue(N); MakeEmpty(q); for each vertex v { if (Indegree[v]==0) Enqueue(V,Q); } while(!IsEmpty(q)) { v = Dequeue(q); for each w adjacent to v { if (--Indegree[v]==0) Enqueue(w,q); } }
4.3 最短路径
单源最短路径问题: 从一个特定顶点s到该图种每个个顶点的最短路径.
4.3.1 无权最短路径
所有边的权值为1.
对于每一个顶点,记录3个值:
- Known: 当前节点有没有被访问过.有则置1
- dv: 当前已知的最短距离
- pv: 路径的上一个节点
一个不太好的算法
- 取起始点,其dv设为0
- currDist递增,初值为0.
- 将当前dv为currDist且没有访问过的节点,访问之: 设置其所有邻接节点的dv和pv;
- 重复2
void Unweighted(Table t) { int currDist; Vertex v,w; for (currDist=0;currDist<Num; currDist++) { for each vertex v { if (!t[v].Known && t[v].Disk == currDist) { t[v].known = 1; for each w adjacent to v { if (t[w].dist == Infinity) { t[w].dist = currDist+1; t[w].path = v; } } } } } }
更好点的算法
- 创建一个空队列,将初始节点放入
- 队列出队,访问: 设置所有邻接点得dv和pv; 将所有邻接点加入队列
- 重复2
void Unweighted(Table t) { Queue q; Vertex v,w; q = CreateQueue(N); MakeEmpty(q); Enqueue(s,q); while(!IsEmpty(q)) { v = Dequeue(Q); t[v].known = 1; for each w adjacent to v { if (t[w].dist == Infinity) { t[w].dist = t[v].dist + 1; t[w].path = v; Enqueue(W,Q); } } } }
4.3.2 赋权最短路径
解决单源最短路径问题的一般方法叫做 Dijkstra算法.
- 选取一个起始点,标记其dv为0
- 访问一个known为0的点,标记其known为1,更新其邻接的所有known为0的点得dv.
4.4 最小生成树
一般是在无向图中考虑.
4.4.1 Prim算法
步骤:
- 选取一个初始点,做为树的根
- 选取一个不在树中得点,要求: 它到树中得节点的距离是其他不在树中节点中最小的.
- 将这个点加入树中.
对每个节点,维护3个值:
- known
- dv: 该节点到树中节点的最短路径
- pv: 到哪个节点
算法步骤:
- 选初始点,放入树中当根
- 对树中的但是known为0的点,去dv最小的一个,访问: known设为1; 更新其邻接的所有点得dv和pv;
4.4.2 Kruskal算法
在所有边上,选择最小的,如果它加入树中,不构成圈,则加入到树中.
算法:
- 把图种所有边,构建成一个堆
- 不断DeleteMin,测试该边的两个顶点是否在同一个集合中.如果在,则不能添加,会成圈.不在,则加入.